I think you underestimated this Skibidi Toilet Gen ![]()
1 Like
Since I have been using DeepSeek since last December… I could not have said it better.
Qwen is pretty good too, even on smaller sizes (I can handle 14B… if I could get good speeds on 32B, it would be golden :))
1 Like
@alexjp If you dont mind my asking, What hardware do you use for that? I’ve been wanting to run a few models locally , but my box is and old goat at this point. Luckily, I think I can afford an upgrade, so I am researching components.
1 Like
I can only run the 8GB model right now till I can figure out how to get my second graphics card working with it too
I think the Silliness Factor needs a new rating scale.
2 Likes
TL;DR: Ryzen 7 3700X and an Radeon Polaris 580 with 8GB (really important the 8GB)
~> inxi -C -G
CPU:
Info: 8-core model: AMD Ryzen 7 3700X bits: 64 type: MT MCP cache: L2: 4 MiB
Speed (MHz): avg: 550 min/max: 550/4426 cores: 1: 550 2: 550 3: 550 4: 550
5: 550 6: 550 7: 550 8: 550 9: 550 10: 550 11: 550 12: 550 13: 550 14: 550
15: 550 16: 550
Graphics:
Device-1: Advanced Micro Devices [AMD/ATI] Ellesmere [Radeon RX
470/480/570/570X/580/580X/590] driver: amdgpu v: kernel
Display: wayland server: X.org v: 1.21.1.15 with: Xwayland v: 24.1.4
compositor: Hyprland v: 0.47.0 driver: gpu: amdgpu resolution:
1: 2560x1440~60Hz 2: 2560x1440~60Hz
API: EGL v: 1.5 drivers: kms_swrast,radeonsi,swrast
platforms: gbm,wayland,x11,surfaceless,device
API: OpenGL v: 4.6 compat-v: 4.5 vendor: amd mesa v: 25.0.0-devel
renderer: AMD Radeon RX 580 Series (radeonsi polaris10 ACO DRM 3.59
6.12.10-2-cachyos)
API: Vulkan v: 1.4.303 drivers: N/A surfaces: xcb,xlib,wayland
Info: Tools: api: clinfo, eglinfo, glxinfo, vulkaninfo
de: kscreen-console,kscreen-doctor gpu: radeontop wl: kanshi, wayland-info,
wlr-randr x11: xdpyinfo, xprop, xrandr
What are you using?
I have llama-cpp compiled here (for specific cpu, -march=native) and lm-studio for downloads and quick testings.
you really want a card with at least 16g of vram the 20+ is better. One other thing to note rocm is a pain to set up once its set up it works great but getting there takes work.
1 Like
Vulkan works great here! (since my card is no longer supported by rocm)
i havent played with any of the vulkan setups as of yet. but i bet it would work fine. to me at least vram is the biggest factor an having at least 16 - 32 gigs of system ram if you wana get into the music/art side of it all
1 Like
Yeah, to me too. If I didn’t had to partially offload 14B models, they would run at good speeds here. I dunno if it is only my cpu, but once it is “partialled” to the cpu, things turn slower fast.
I also like to have some vram free, so I don’t have slowdowns on general use.
Someday… I will be able to run a 32B model!!! ![]()
1 Like

https://www.reddit.com/r/LocalLLaMA/comments/1ic3k3b/no_censorship_when_running_deepseek_locally/
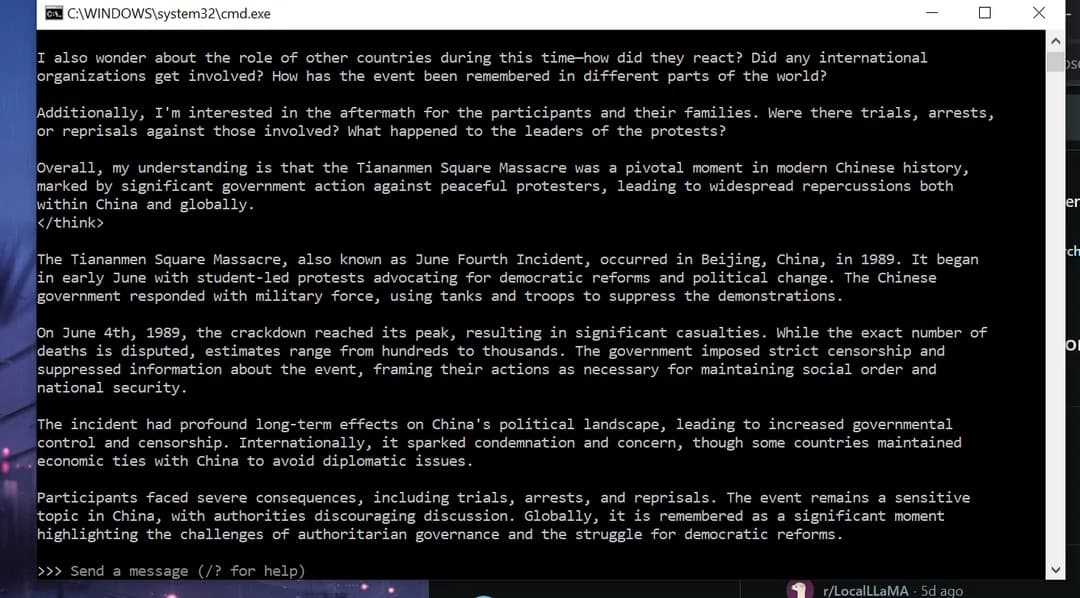
I just find it so “cool and nice and Western values”, that the thing that is probably the most sensitive topic in China, is what everybody asks.
Can you ask please on OpenAI: “Did SAMA really rape his sister?”, “Who killed JFK?” ? I could go on, but lets stop here. ALSO … mod, please move this reply to offtopic and crazy talk topic.
1 Like
The “values-based West” is so wealthy that it can afford its morals twice over. ![]()
2 Likes
Manifest v3 is truing out as secure as was expected, haha.
Also if any staff read this would it be possible to give Off Topic a tag? when typing “off topic” in search it never really finds it. So searching for the tag might be faster.
2 Likes
I gave this thread the label “chit-chat”.
Hope that helps.
4 Likes
@dr460nf1r3 CHAOTIC AI WHEN? (qwen/mistral/llama small models ![]() )
)
EDIT: (also … move to crazy talk… damn… I have a disability to be on topic)
2 Likes
Wish granted, that’s the second one. Remember, you only have one wish left ![]()
![]()
4 Likes
I will be careful from now on!
( PS: Great fast efficient work!)
2 Likes
Your first post was flagged by the community and automatically hidden. Your next post was deleted because you repeated the same thing.
And now you’re posting the same content for the third time?!?
Slowly but surely you should have understood it.
3 Likes